DeepMind 发布超真实世界模型 Genie 3, AGI 向前一步
就在昨晚,谷歌宣布推出通用型世界模型Genie3。用户可通过文本提示生成动态世界,以每秒24帧的速度进行实时交互。更重要的是,Genie3的生成内容可在720p分辨率下维持物理一致性“几分钟时间”,远超此前世界模型读秒级水平。
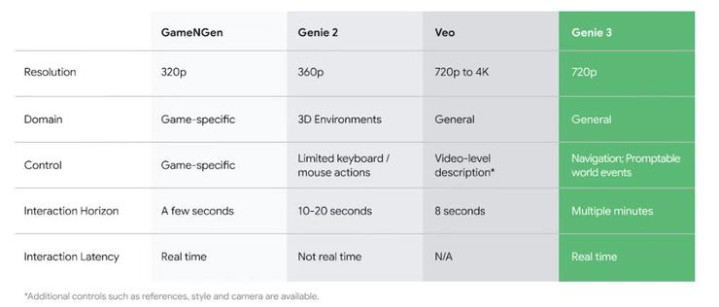
根据DeepMind的说法,Genie3是首个允许实时交互的世界模型。相较于该系列前作Genie2、游戏生成引擎GameNGen以及视频生成模型Veo,Genie3在生成内容的连贯性上堪称质的飞跃,同时分辨率、交互性、延迟均在一流水平。
Genie3在业内人士之间也广受好评。英伟达高级科学家的JimFan称其是Genie1基础上的“量子飞跃”。DeepMind前科学家TejasKulkarni专门为其撰写长评,不仅高度评价Genie3在通用性、物理规律、视觉记忆等方面的表现,更是称之为“实现AGI之前的最后一块拼图”。但同时,也指出其在多主体互动和长指令跟随方面存在明显缺陷。
目前研究团队正为Genie3寻找更多测试者,其中一个被寄予厚望的应用场景是训练工具。不仅人类学生可以借助世界模型进行学习、积累经验,对于Agent来说,世界模型也意味着在多样化的交互环境中进行不断训练和性能评估成为可能。Agent有望借此理解其行为如何影响环境的变化,并学着预测环境的演变。
“世界模型是通往通用人工智能(AGI)道路上的关键里程碑。”该团队表示。
连贯性质变:从秒级到分钟级
Genie3甫一发布便引起热议,甚至有用户@el.cine将其比作又一个GPT时刻。
Genie3研发团队的MattMcGill分享了自己生成的视频,称自己让角色试着”低头看看鞋,看模型是否理解什么是水坑”。用户@Boston|CapxAI在其评论区感叹:“谷歌街景。”
看到Genie3的生成效果,用户@TheCanaanite提醒DeepMind看好自家工程师,“Zuck已经在提着十亿年薪赶来的路上。”
Genie3令人惊喜之处在于,其模拟真实世界时已不需要靠着高糊画面以假乱真,是依循真实物理规律的交互表现,和相对连贯的生成内容,让用户感到画面可信。
据DeepMind官方介绍,Genie3的功能具体包括:
模拟世界的物理属性:展现自然现象如水与光照,以及自然环境中的复杂交互;
模拟自然世界:从动物行为到错综复杂的植物生命,生成充满活力的生态系统;
建模动画和小说:激发想象力,创造奇幻场景和富有表现力的动画角色;
探索地点和历史背景:超越地理和时间的界限,探索不同的地方和过去的时代;
为了让AI生成的世界具有沉浸感,它们必须在长时间尺度上保持物理一致性。但基于自回归技术生成三维环境,通常比生成视频更具技术挑战性,因为误差往往会随着时间的推移而累积。
与传统的视频生成模型不同,Genie3通过在每一帧的自回归生成过程中,将此前的生成轨迹同步纳入计算以解决这一挑战。例如用户在世界模型中走上了一分钟之前的回头路,模型也就必须参考一分钟之前的相关信息。
用户每一次完成输入,这种计算便宣告开始,每秒钟进行多次。在用户和Genie3的实时交互过程中,这一循环周而复始,由此三维场景的一致性从秒级提升至分钟级。
Genie3研发团队支持,通过NeRF和GaussianSplatting等方法也能实现连贯的可交互3D环境,但它们依赖于用户提供明确的3D指示。而Genie3的连贯性实质上是一种涌现能力,3D环境基于世界描述和用户操作被逐帧创建,从而更具动态、富于变化。
Genie3还提供了一种新的基于文本的交互形式。除了前进后退,用户还能在其生成的三维场景中“呼风唤雨”。在DeepMind官方文档中,这被称为“可提示世界事件”。
这类事件意在改变已生成的世界,如修改天气状况,或引入新的物体和角色,从而增强从导航控制中获得的体验。
对于Agent而言,这种交互形式意味着其在与环境的交互过程中可以设想更多“如果……会怎样”的场景。这些场景将成为Agent提供学习如何应对意外情况的经验。
具身AGI向前一步
热度之下,Genie3的局限性也同样突出:
行动空间有限:尽管可提示的世界事件允许进行广泛的环境干预,但这些干预不一定由Agent自身执行。Agent能够直接执行的行动范围目前受到限制;
与其他智能体的交互与模拟:在共享环境中准确建模多个独立智能体之间的复杂交互,仍然是一个持续的研究挑战;
精确呈现真实世界位置:Genie3目前无法以完美的地理精度模拟真实世界位置;
文本渲染:通常只有在输入的世界描述中提供时,才能生成清晰易读的文本;
交互时间有限:Genie3目前仅支持几分钟的连续交互,而不是数小时;
然而毋庸置疑的是,世界模型刚刚向我们的世界迈出了一大步。
用户@BilawalSidhu用同一个场景对比了Genie2和Genie3的表现。短短七个月时间,已然天差地别。
此前的世界模型,大多难以兼顾实时交互效果和物理一致性。根据用户提示渲染出的世界,可能在任何一帧分崩离析。而Genie3发布后,研发团队的@JackParker-Holder则表示我们已经站在了世界模型的分水岭上,用户可以生成任何其想象中的世界,并进行多分钟的实时交互模拟。更为长远的意义在于,“这或许就是具身AGI的关键缺失部分。”
在DeepMind官方文件中,有一个特别的Genie3用例。研究团队将专门应用于3D虚拟环境的通用Agent“SIMA”置于Genie3生成的虚拟世界中,并为其设定了一组目标。
虽然与此前的世界模型一样,Genie3并不了解SIMA的目标,而是根据其动作模拟未来。但在Genie3生成的虚拟世界中,更稳定的物理一致性使SIMA可以执行更长的动作序列、实现更复杂的目标,这一突破对于迈向通用人工智能有着至关重要的作用。
在不久前刚刚结束的WAIC上,RichSutton曾形容AI是“创造事物的事物”。GPT-4发布不到三年,我们可以借助AI创造的对象就从文本、代码跃升到了无限瑰丽的想象世界。
回到Genie3发布时,DeepMind提出的问题:如果你不仅可以观看生成的视频,还可以探索它,将会怎样?
在那个世界里,我们可上九天揽月,也可以化身自己的小狗,在海边漫步。