新研究: 人类读指针式时钟准确率达 89.1%, 顶尖 AI 仅 13.3%
IT之家9月14日消息,一项新研究发现,人类读取指针式时钟的准确率可达89.1%,而目前最优秀的人工智能(AI)模型准确率仅为13.3%,该结果凸显出当前语言模型在视觉推理能力方面与人类存在巨大差距。
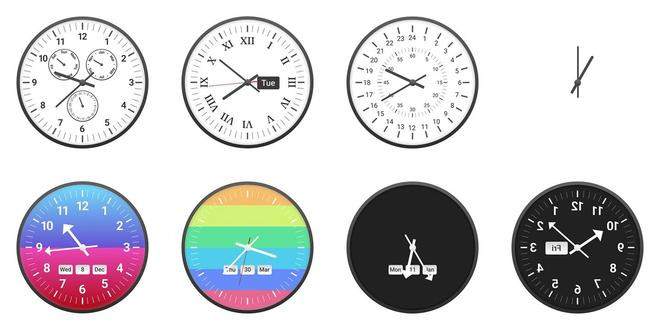
阿莱克・萨法尔(AlekSafar)采用名为“ClockBench”的全新测试,让来自6家企业的11个大型语言模型与5名人类展开正面较量。该基准测试包含180个定制的指针式时钟及720道测试题,遵循“人类易上手、AI难突破”的设计思路,这一思路在ARC-AGI、SimpleBench等基准测试中也有所体现。
为确保公平性并避免与模型训练数据重叠,萨法尔从零开始构建了该数据集。数据集包含36种独特的钟面设计,融合了罗马数字与阿拉伯数字、不同朝向、时针标识、镜像布局及彩色背景等元素。每种设计他都制作了5个不同的时钟,总共有180个时钟。
每个时钟均通过四类问题进行测试:读取时间、时间计算、按特定角度调整指针,以及时区转换。萨法尔根据时钟类型设置了不同的误差允许范围,例如,仅含时针的时钟比同时具备时针、分针、秒针的时钟误差容忍度更高。
萨法尔表示,相较于“人类终极测试”(Humanity'sLastExam)这类侧重知识储备的测试,ClockBench对AI模型的难度更高。测试结果表明,即便面对看似简单的视觉任务,AI与人类的差距仍十分显著。
谷歌旗下的Gemini2.5Pro模型以13.3%的准确率位居榜首,Gemini2.5Flash紧随其后,准确率为10.5%。GPT-5排名第三,准确率8.4%,且调整模型的推理预算对提升准确率效果甚微。
Grok4模型表现垫底,准确率仅0.7%,这一结果颇为出人意料,因为该模型在其他基准测试中常常表现出色。Grok4将63.3%的时钟判定为“无效”,但实际上180个时钟中仅37个显示的是“不可能时间”。这种极度谨慎的方式意味着,从技术层面来讲,Grok4的正确答案数量最多,但这只是通过随机将时钟标记为无效实现的。
Anthropic公司的Claude4Sonnet(准确率4.2%)与Claude4.1Opus(准确率5.6%)表现同样不佳。研究还发现,61.7%的时钟未能被任何一个AI模型正确读取。
相较于准确率,误差的严重程度更能反映问题本质。人类读取时间的中位误差仅为3分钟,而表现最佳的AI模型中位误差达1小时,性能最差的AI模型误差约为3小时,对于12小时制时钟而言,这几乎和随机猜测差不多。
IT之家注意到,部分钟面特征对AI而言难度极高:当钟面采用罗马数字时,AI准确率降至3.2%;采用圆形数字时,准确率仅为4.5%。此外,秒针、彩色背景及镜像布局也会对AI的判断造成干扰。
仅含时针的时钟对AI而言相对容易(准确率23.6%),这得益于其更高的误差容忍度。采用阿拉伯数字和基础表盘的标准时钟,也能让AI取得相对更好的成绩。
测试还获得了一个意外发现:当AI模型成功读取时间后,它们在时间计算、指针调整或时区转换任务中几乎都能得出正确结果。这意味着,AI面临的挑战并非“进行时间相关的数学运算”,而是“从视觉信息中读取时间”这一初始步骤。
萨法尔认为,背后原因可能有三点:其一,读取指针式时钟对视觉推理能力是一项严峻考验;其二,罕见或特殊的钟面设计在训练数据中出现频率极低;其三,将钟面视觉信息转化为文字描述,对当前AI模型而言很可能是一项难题。
ClockBench被定位为一项长期基准测试。其完整数据集目前处于保密状态,以避免污染未来AI的训练过程,但已有一个规模较小的公开版本可供测试使用。
尽管AI在该测试中的得分普遍较低,萨法尔仍看到了希望:性能最佳的模型表现优于随机猜测,且展现出基础的视觉推理能力。不过,这些能力能否通过“扩大现有方法规模”得到提升,还是需要全新技术路径来突破,目前仍是一个待解的问题。
一年前,中国一项研究也曾发现多模态语言模型存在类似的能力短板,但当时的结果要好得多。彼时,GPT-4o模型在包含“读时钟、读仪表”的仪表盘任务中,准确率达到54.8%。而此次ClockBench测试中,AI的最高准确率仅为13.3%,这一差距既表明新基准测试难度显著提升,也反映出AI的时钟读取能力并未取得明显进步。